
이전 글
[코루틴의 정석] async와 Deferred(Chapter5)
[코루틴의 정석] 코루틴 빌더와 Job(Chapter4-2)
[코루틴의 정석] 코루틴 빌더와 Job(Chapter4-1)
개요
구조화된 동시성의 원칙이란 비동기 작업을 구조화함으로써 비동기 프로그래밍을 보다 안정적이고 예측 가능할 수 있게 만드는 원칙이다.
코루틴은 부모-자식 관계로 구조화함으로써 보다 안전하게 관리되고 제어될 수 있도록 한다.
코루틴을 부모-자식 관계로 구조화하는 방법은 간단하다.
부모 코루틴을 만드는 코루틴 빌더의 람다식 속에서 새로운 코루틴 빌더를 호출하면 된다.
fun main() = runBlocking {
launch {
// 부모 코루틴
launch {
// 자식 코루틴
}
}
}위 코드를 구조화하면 다음과 같다.
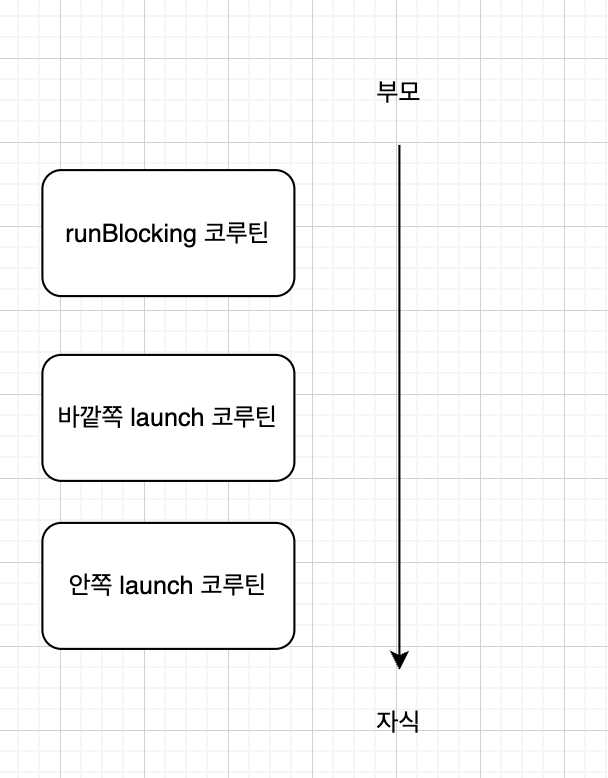
구조화된 코루틴은 다음과 같은 여러 특징을 갖는다.
- 부모 코루틴의 실행 환경이 자식 코루틴에게 상속
- 작업을 제어하는 데 사용
- 부모 코루틴이 취소되면 자식 코루틴도 취소된다.
- 부모 코루틴은 자식 코루틴이 완료될 때까지 대기한다.
- CoroutineScope를 사용해 코루틴이 실행되는 범위를 제한할 수 있다.
실행 환경 상속
부모 코루틴의 실행 환경 상속
부모 코루틴이 자식 코루틴을 생성하면 부모 코루틴의 CoroutineContext가 자식 코루틴에게 전달된다.
fun main() = runBlocking<Unit> {
val coroutineContext = newSingleThreadContext("MyThread") + CoroutineName("CustomCoroutine")
launch(coroutineContext) {
println("[${Thread.currentThread().name}] 부모 코루틴 실행")
launch {
println("[${Thread.currentThread().name}] 자식 코루틴 실행")
}
}
}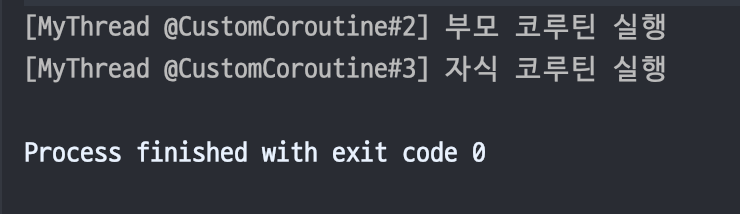
부모 코루틴은 coroutineContext에 설정된 대로 MyThread 스레드를 사용해 실행되고 코루틴 이름이 설정된 것을 확인할 수 있다.
자식 코루틴은 coroutineContext를 설정하지 않았지만, 부모 코루틴과 이름이 같은 것을 볼 수 있다.
같은 이유는 부모 코루틴의 실행 환경을 담는 CoroutineContext 객체가 자식 코루틴에게 상속되기 때문이다.
실행 환경 덮어쓰기
하지만 부모 코루틴의 모든 실행 환경이 항상 자식 코루틴에게 상속되지는 않는다.
자식 코루틴 빌더에게 새로운 실행 환경이 전달되면 CoroutineContext 구성 요소들은 덮어씌워진다.
fun main() = runBlocking<Unit> {
val coroutineContext = newSingleThreadContext("MyThread") + CoroutineName("ParentCoroutine")
launch(coroutineContext) {
println("[${Thread.currentThread().name}] 부모 코루틴 실행")
launch(CoroutineName("ChildCoroutine")) {
println("[${Thread.currentThread().name}] 자식 코루틴 실행")
}
}
}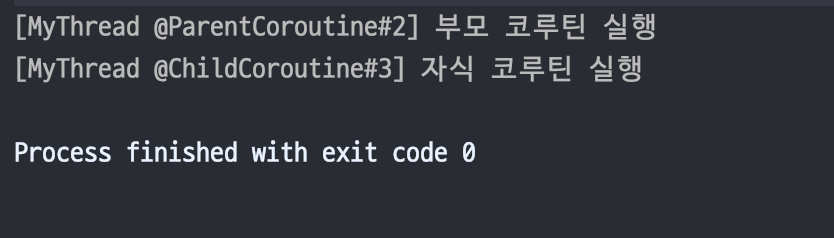
자식 코루틴 빌더에 context 인자로 전달된 CoroutineContext는 부모 코루틴에게 전달받은 CoroutineContext을 덮어 씌운다.
부모와 자식 코루틴의 CoroutineContext 객체에 CoroutineName이 중복으로 포함돼 있다면 자식 코루틴 빌더의 CoroutineName이 사용된다.
이처럼 자식 코루틴 빌더에 새로운 객체를 전달함으로써 부모 코루틴으로부터 전달된 CoroutineContext를 재정의 할 수 있다.
하지만 Job 객체는 상속되지 않고 코루틴 빌더 함수가 호출되면 새롭게 생성되는 것을 주의해야 한다.
상속되지 않는 Job
앞에서 다뤘듯이 모든 코루틴 빌더 함수는 호출 때마다 Job 객체를 생성한다.
코루틴 제어에 Job 객체가 필요한데 Job 객체를 부모 코루틴으로부터 상속받게 되면 코루틴의 제어가 어려워지기 때문에, 코루틴들은 서로 다른 Job을 가진다.
fun main() = runBlocking<Unit> {
val runBlockingJob = coroutineContext[Job]
launch {
val launchJob = coroutineContext[Job]
if (runBlockingJob == launchJob) {
println("job is same")
} else {
println("job is not same")
}
}
}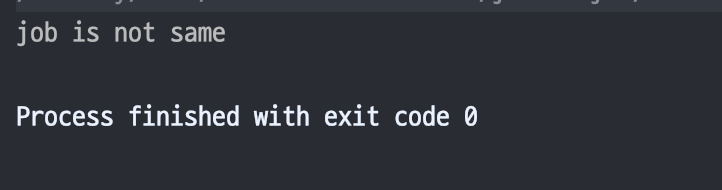
코드의 실행 결과를 보면 runBlocking과 launch 블록의 Job 객체가 다른데, 이는 실행 환경을 상속받았음에도 서로 다른 Job 객체를 가진다는 것을 확인할 수 있다.
하지만 부모 코루틴의 Job과 자식 코루틴의 Job이 아무 관계가 없는 것은 아니다.
이 두 관계는 코루틴을 구조화하는 데 사용된다.
구조화에 사용되는 Job
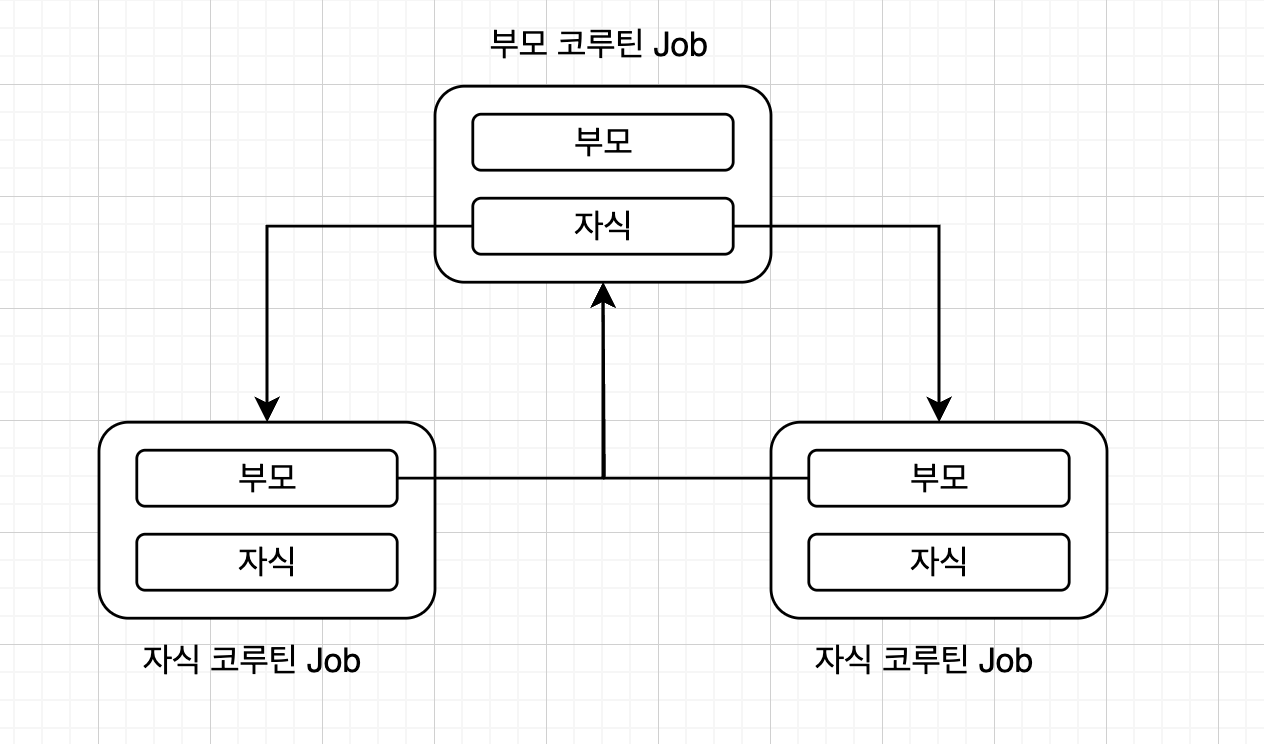
코루틴 빌더가 호출되면 Job 객체는 새롭게 생성되지만 위 그림과 같이 내부 정의된 프로퍼티를 통해 부모 <->자식 양방향 참조를 가진다.
프로퍼티는 부모 프로퍼티와 자식 프로퍼티로 나뉜다.
코루틴은 하나의 부모 코루틴만을 가질 수 있기 때문에 Job 객체를 가리키는 프로퍼티의 타입은 Job?이다.
부모를 가지는데, 최상위 부모(루트 코루틴)는 부모가 없을 수 있기 때문에 nullable 타입이 된다.
또한 코루틴은 하위에 여러 자식을 가질 수 있기 때문에, child 프로퍼티의 타입은 Sequence<Job>이다.
해당 내용을 표로 정리하면 다음과 같다.
| Job 프로퍼티 | Type | 설명 |
| parent | Job? | 부모 코루틴은 최대 한개이며, 없을 수도 있다. |
| children | Sequence<Job> | 코루틴은 복수의 자식 코루틴을 가질 수 있다. |
코루틴의 구조화와 작업 제어
코루틴의 구조화는 하나의 큰 비동기 작업을 작은 비동기 작업으로 나눌 때 일어난다.
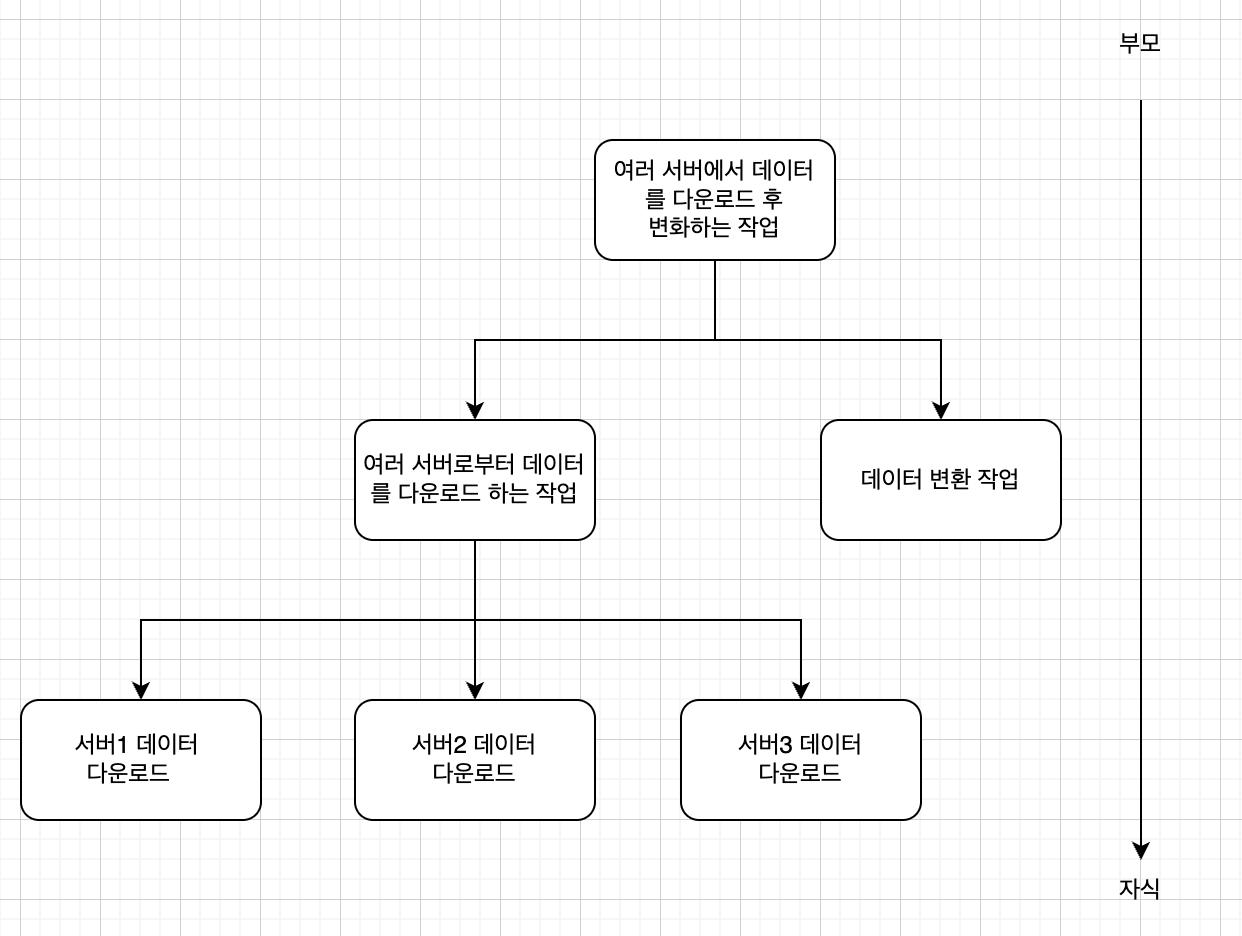
예시라기보단, 다음과 같이 비동기 작업도 작은 비동기 작업으로 분할할 수 있다는 느낌만 감을 잡으면 될 것이다.
위 작업을 코루틴으로 바꾸면, 여러 서버로부터 데이터를 다운로드하는 코루틴과 데이터를 변환하는 코루틴을 합친 코루틴이 될 것이다.
코루틴을 구조화하는 가장 중요한 이유는 코루틴을 안전하게 관리하고 제어하기 위함이다.
구조화된 코루틴은 다음과 같은 특성이 있다.
- 코루틴으로 취소가 요청되면서 자식 코루틴으로 전파된다.
- 부모 코루틴은 모든 자식 코루틴이 완료돼야 완료될 수 있다.
취소의 전파
코루틴은 자식 코루틴으로 취소를 전파하는 특성을 갖기 때문에 특정 코루틴이 취소되면 하위의 코루틴이 취소된다.
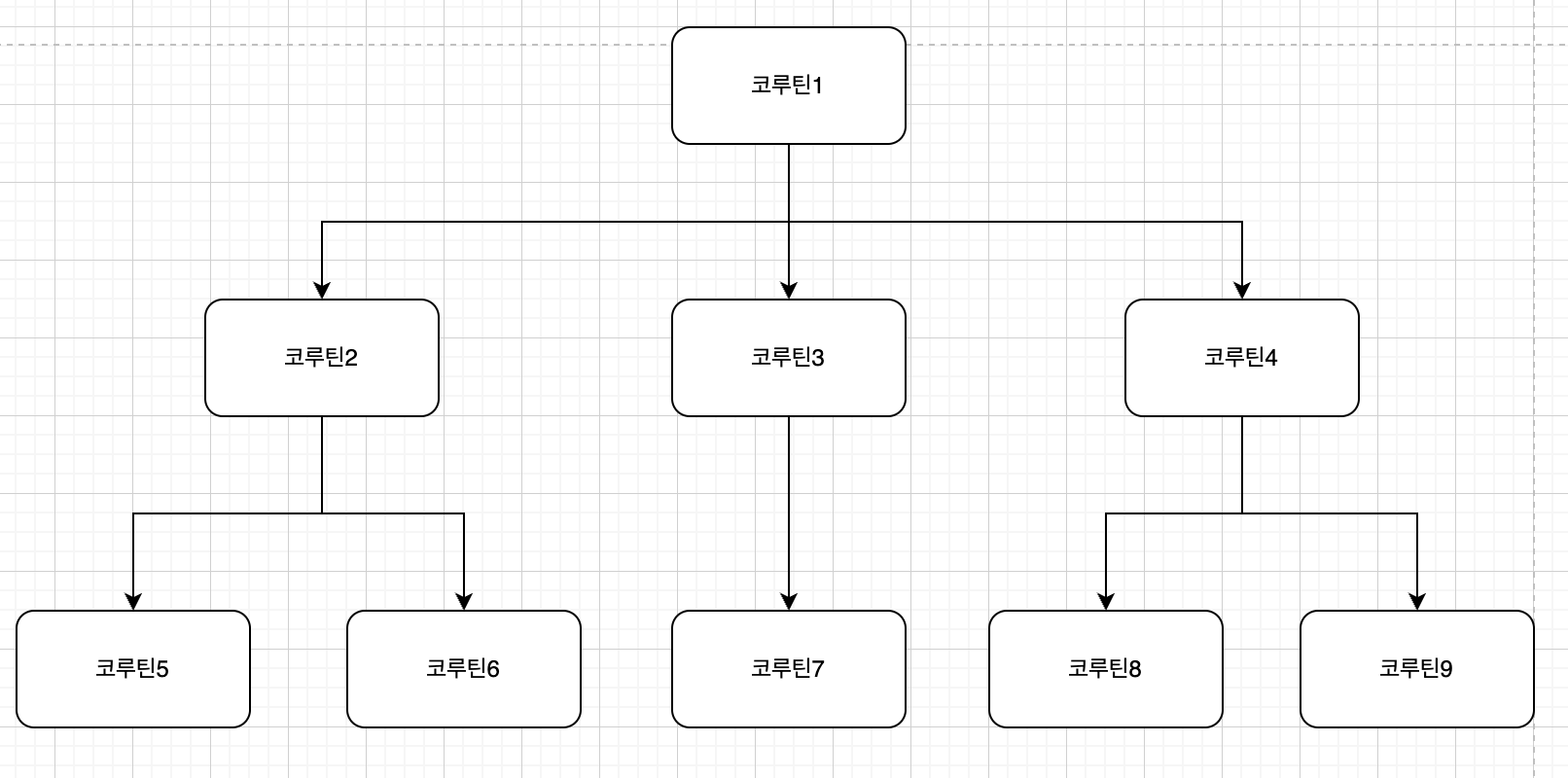
코루틴 1에 취소가 요청되면 어떻게 될까?
위에서 코루틴은 자식 코루틴으로 취소를 전파하는 특성이 있기 때문에, 코루틴 2, 3, 4에 취소가 요청되고,
각각의 코루틴은 자식에게 취소를 전파할 것이다.
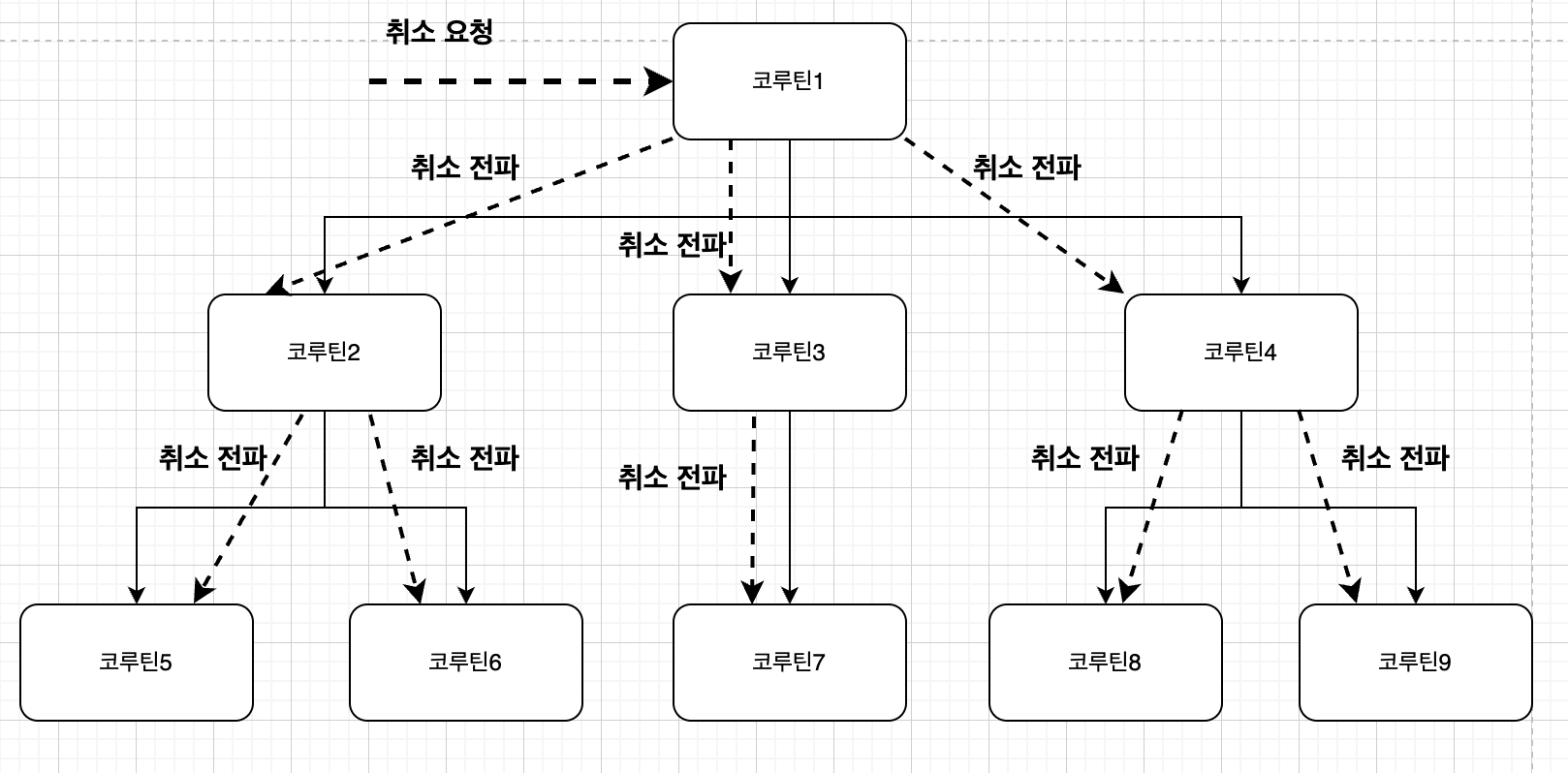
코루틴 2에 취소가 요청된다면 5와 6, 3일 경우 7, 4일 경우 8,9에 취소가 전파된다.
즉, 특정 코루틴에 취소가 요청되면 취소는 자식 코루틴 방향으로만 전파되며, 부모 코루틴으로는 취소가 전파되지 않는다.
fun main() = runBlocking<Unit> {
val startTime = System.currentTimeMillis()
val parentJob = launch(Dispatchers.IO) {
val dbResultsDeferred = listOf("DB1", "DB2", "DB3").map {
async {
delay(1000L)
println("[${getElapsedTime(startTime)}] ${it}으로부터 데이터를 가져오는데 성공했습니다.")
"[$it data]"
}
}
val result = dbResultsDeferred.awaitAll()
println(result)
}
}위 코드는 3개의 데이터베이스로부터 데이터를 가져와 병합하는 코루틴이다.

만약 작업 중간에 부모 코루틴이 취소됐다고 가정해 보자.
그러면 자식 코루틴의 작업은 더 이상 진행할 필요가 없고, 진행할 경우 자원을 낭비하는 것이다.
fun main() = runBlocking<Unit> {
val startTime = System.currentTimeMillis()
val parentJob = launch(Dispatchers.IO) {
val dbResultsDeferred = listOf("DB1", "DB2", "DB3").map {
async {
delay(1000L)
println("[${getElapsedTime(startTime)}] ${it}으로부터 데이터를 가져오는데 성공했습니다.")
"[$it data]"
}
}
val result = dbResultsDeferred.awaitAll()
println(result)
}
println("[${getElapsedTime(startTime)}]")
parentJob.cancel()
}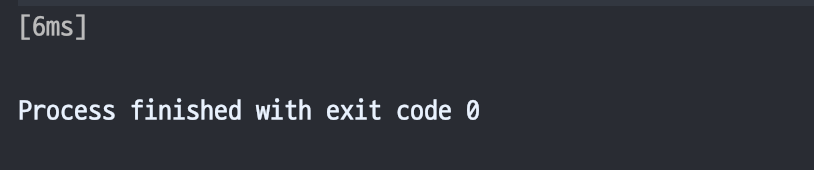
1000 ms가 되기 전에, cancel 함수를 통해 부모 코루틴이 중단되고, 자식 코루틴도 모두 취소되기 때문에 작업이 진행되지 않은 것을 확인할 수 있다.
부모 코루틴은 자식 코루틴이 완료돼야 완료될 수 있지만, 자식 코루틴의 실행 완료를 기다리기 전까지 Job의 상태는 실행 완료 중이라는 상태를 가진다.
실행 완료는
- isActive : true
- isCancelled : false
- isCompleted : false
의 값을 가지는데, 이는 실행 중 상태와 동일하다.
따라서 실행 완료와 실행 중 상태는 구분하기 어려워서, 구분 없이 사용한다.
CoroutineScope 사용해 코루틴 관리하기
CoroutineSocpe 객체는 자신의 범위 내에서 생성된 코루틴들에게 실행 환경을 제공하고, 실행 범위를 관리하는 역할을 한다.
CoroutineScope를 생성하는 방법은 2가지가 있다.
인터페이스 구현을 통한 생성
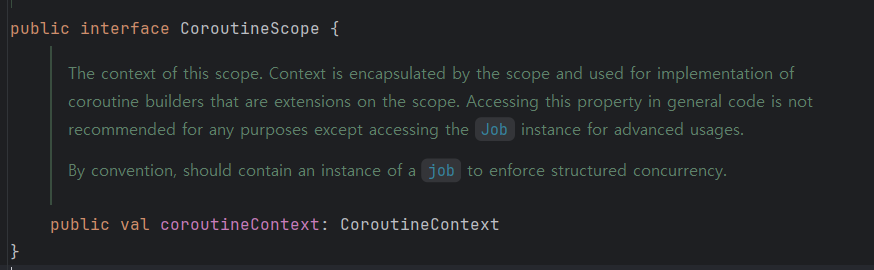
CoroutineScope 인터페이스는 다음과 같이 선언돼 있다.
코루틴의 실행 환경인 CoroutineContext를 가진 단순한 인터페이스로 이 인터페이스를 구현한 구체적인 클래스를 사용하면 CoroutineScope 객체를 생성할 수 있다.
함수를 통한 생성
CoroutineScope 객체를 생성하는 또 다른 방법은 CoroutineScope 함수를 사용하는 것이다.

CoroutineScope 함수는 CoroutineScope를 인자로 입력받아 CoroutineScope 객체를 생성하며, Job 객체가 없을 경우 새로운 Job 객체를 생성한다.
따라서 CoroutineScope(Dispatchers.IO)를 호출하면 Dispatchers.IO와 새로운 Job 객체로 구성된 CoroutineContext를 가진 CoroutineScope 객체를 생성할 수 있다.
fun main() = runBlocking<Unit> {
val coroutineScope = CoroutineScope(Dispatchers.IO)
coroutineScope.launch {
delay(100L)
println("${Thread.currentThread().name}] 코루틴 실행 완료")
}
Thread.sleep(1000L)
}
이 코드에서 coroutineScope 변수는 CoroutineScope(Dispatchers.IO)가 호출돼 만들어진 CoroutineScope 객체를 가리킨다.
따라서 코드를 실행해 보면 launch 코루틴이 Dispatchers.IO에 의해 백그라운드 스레드로 보내져 실행되는 것을 확인할 수 있다.
이처럼 두 가지 방법으로 CoroutineScope 객체를 만들 수 있는데, 이 과정에서 CoroutineScope 내부에서 실행되는 코루틴이 CoroutineScope로부터 CoroutineContext를 제공받는다는 사실이 중요하다.
그러면 CoroutineScope는 어떻게 코루틴에게 CoroutineContext를 제공할 수 있을까?
코루틴에게 실행 환경을 제공하는 CoroutineScope
이를 살펴보기에 앞서, launch 코루틴 빌더 함수가 어떻게 선언돼 있는지 알아봐야 한다.
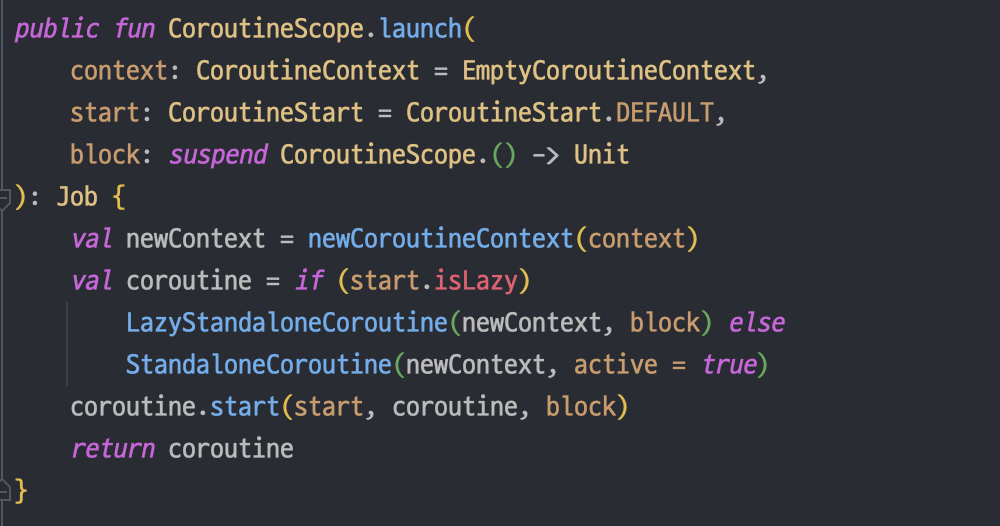
이 코드에서 launch 코루틴 빌더 함수는 CoroutineScope의 확장 함수로 선언돼 있으며, launch 함수가 호출되면 다음 과정을 통해 CoroutineScope 객체로부터 실행 환경을 제공받아 코루틴의 실행 환경을 설정한다.
- 수신 객체인 CoroutineScope로부터 CoroutineContext 객체를 제공받는다.
- 제공받은 CoroutineContext 객체에 launch 함수의 context 인자로 넘어온 CoroutineContext를 더한다.
- 생성된 CoroutineContext에 코루틴 빌더 함수가 호출돼 새로 생성되는 Job을 더한다. 이때 CoroutineContext를 통해 전달되는 Job 객체는 새로 생성되는 Job 객체의 부모 Job 객체가 된다.
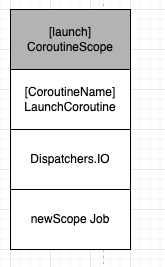
val newScope = CoroutineScope(CoroutineName("MyCoroutine")+Dispatchers.IO)이 코드는 다음과 같이 동작한다.
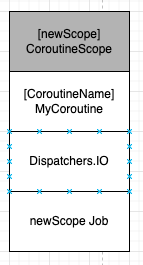
위 그림은 newScope의 CoroutineContext 객체이다.
코드에서 선언된 CoroutineName과 Dispatchers.IO와 생성된 newScope의 Job로 구성되어 있다.
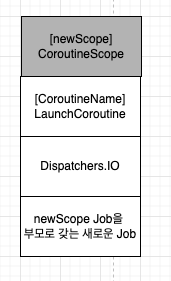
val newScope = CoroutineScope(CoroutineName("MyCoroutine")+Dispatchers.IO)
newScope.launch(CoroutineName("LaunchCoroutine")) {
...newScope의 launch 함수를 통해 생성되는 CoroutineContext 객체는 다음과 같다.
자식 코루틴은 부모 코루틴의 CoroutineContext 객체를 상속받는데, 그 과정에서 CoroutineName이 넘어왔으므로, 덮어씌워진다.
val newScope = CoroutineScope(CoroutineName("MyCoroutine")+Dispatchers.IO)
newScope.launch(CoroutineName("LaunchCoroutine")) {
val launchJob = this.coroutineContext[Job]
val newScopeJob = newScope.coroutineContext[Job]
...
launch 코루틴 빌더 함수는 새로운 Job을 생성하고, 이 Job은 반환된 CoroutineContext의 Job을 부모로 설정한다.
최종적인 코드이다.
fun main() = runBlocking<Unit> {
val newScope = CoroutineScope(CoroutineName("MyCoroutine")+Dispatchers.IO)
newScope.launch(CoroutineName("LaunchCoroutine")) {
println(this.coroutineContext[CoroutineName])
println(this.coroutineContext[CoroutineDispatcher])
val launchJob = this.coroutineContext[Job]
val newScopeJob = newScope.coroutineContext[Job]
println("launchJob?.parent == newScopeJob >> ${launchJob?.parent == newScopeJob}")
}
Thread.sleep(1000L)
}
여기서 확인하고 싶은 내용은 newScope의 coroutineContext 객체의 이름과 Dispatcher 그리고 Job들의 부모-자식 관계이다.
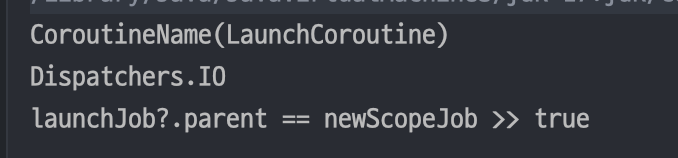
이는 부모 코루틴이 자식 코루틴으로 실행 환경을 상속하는 방식과 완전히 동일하다.
동일한 이유는 실제로 코루틴이 부모 코루틴의 CoroutineContext 객체를 가진 CoroutineScope 객체로부터 실행 환경을 상속받기 때문이다.
launch, runBlocking, async 같은 코루틴 벌다 함수의 람다식에서 this.~ 를 통해 코루틴의 실행 환경에 접근할 수 있는 이유는 CoroutineScope가 수신 객체로 제공됐기 때문이다.
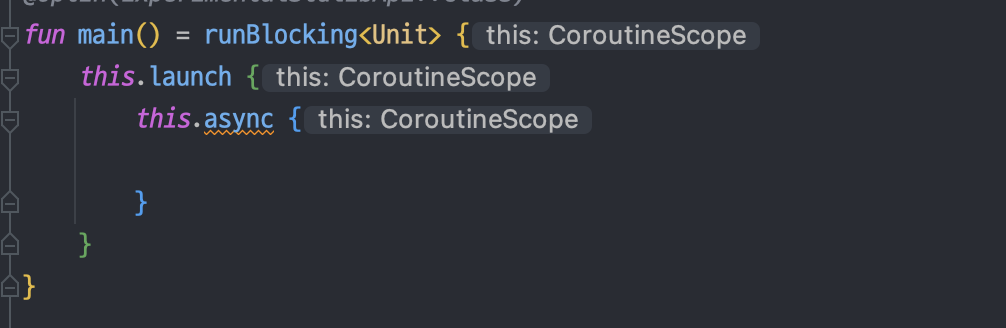
CoroutineScope에 속한 코루틴의 범위
launch, async와 같이 코루틴 빌더의 람다식은 CoroutineScope 객체를 수신 객체로 가진다.
CoroutineScope 객체는 기본적으로 특정 범위의 코루틴을 제어하는 역할을 한다.
fun main() = runBlocking<Unit> {
launch(CoroutineName("Coroutine1")) {
launch(CoroutineName("Coroutine3")) {
println("[${Thread.currentThread().name}] 코루틴 실행")
}
launch(CoroutineName("Coroutine4")) {
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
launch(CoroutineName("Coroutine2")) {
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
위 코드는 runBlocking 람다식 내에서, Coroutine1, Coroutine2라는 2개의 자식 코루틴을 실행하고 있으며,
Coroutine1은 Coroutine3, Coroutine4를 자식 코루틴으로 가지고 있다.
그럼 각 CoroutineScope 객체의 범위를 알아보자.
runBlocking의 수신 객체로 제공되는 CoroutineScope의 범위는 전체이다.
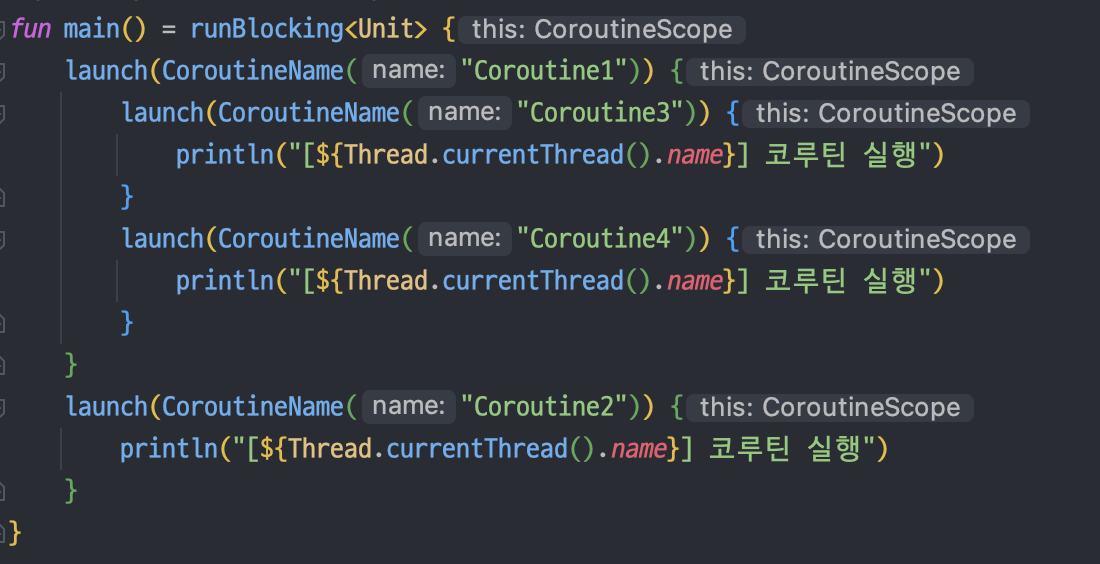
CorotuineScope1의 범위는 다음과 같다.
즉, 코루틴 빌더 람다식에서 수신 객체로 제공되는 CoroutineScope 객체는 코루틴 빌더로 생성되는 코루틴과 람다식 내에서 CoroutineScope 객체를 사용해 실행되는 모든 코루틴을 포함한다.
CoroutineScope를 새로 생성해 기존 CoroutineScope 범위 벗어나기
앞서 다룬 코드들에서 모든 코루틴들은 runBlocking 람다식의 CoroutineScope 객체의 범위에 포함된다.
만약 벗어나기 위해서는 어떻게 해야 할까?
방법은 새로운 CoroutineScope 객체를 생성하고, 이 객체를 사용해 코루틴을 실행하면 된다.
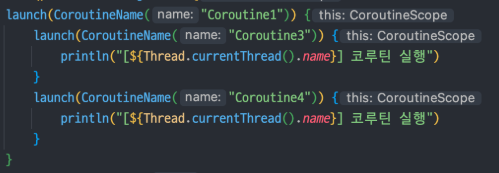
fun main() = runBlocking<Unit> {
launch(CoroutineName("Coroutine1")) {
launch(CoroutineName("Coroutine3")) {
println("[${Thread.currentThread().name}] 코루틴 실행")
}
CoroutineScope(Dispatchers.IO).launch(CoroutineName("Corotuine4")) {
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
launch(CoroutineName("Coroutine2")) {
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
이렇게 새로운 CoroutineScope 객체를 생성하면 기존 CoroutineScope 객체의 범위를 벗어날 수 있다.
이게 가능한 이유는 CoroutineScope가 호출되면 생성되는 새로운 Job 객체에 있다.
코루틴은 Job 객체를 사용해 구조화되는데, CoroutineScope 함수를 사용해 새로운 객체를 생성하면 기존 계층 구조를 따르지 않게 되는 새로운 Job 객체가 생성되기 때문이다.
이렇게 새로운 계층 구조가 만들어지면서 Coroutine4는 runBlocking 코루틴과 아무 관련이 없어진다.
하지만 이렇게 코루틴의 구조화를 깨는 것은 비동기 작업을 안전하지 않게 만들기 때문에 지양해야 한다.
CoroutineScope 취소하기
CoroutineScope 인터페이스는 확장 함수로 cancel 함수를 지원한다.
CoroutineScope 객체의 범위에 속한 모든 코루틴을 취소하는 함수로 범위 내에서 실행 중인 모든 코루틴에 취소가 요청된다.
fun main() = runBlocking<Unit> {
launch(CoroutineName("Coroutine1")) {
launch(CoroutineName("Coroutine3")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
launch(CoroutineName("Coroutine4")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
this.cancel()
}
launch(CoroutineName("Coroutine2")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}위 코드에서는 Coroutine1 코루틴의 CoroutineScope 객체에 취소 요청을 한다.
따라서 범위에 속한 #1, #3, #4는 실행 도중 취소되며, #2 코루틴만 끝까지 실행된다.

cancel 함수의 내부에는 Job 객체에 접근한 후 cancel 함수를 호출한다.
#1 코루틴의 Job이 취소되면 자식 코루틴인 #3, #4의 Job에게 취소가 전파돼 모든 자식 코루틴들이 취소된다.
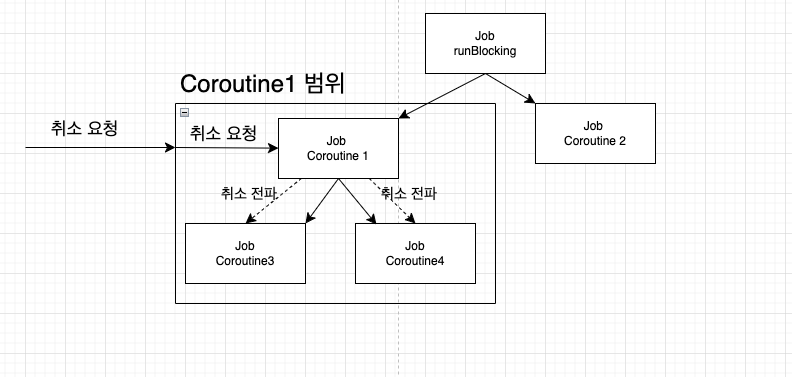
구조화와 Job
코루틴의 구조화의 중심에는 Job 객체가 있다.
실제로 취소 요청을 하면 CoroutineScope 객체 내의 Job 객체에 취소 요청을 보내는 것처럼 실제 동작은 Job 객체를 조작하는 것이다.
runBlocking과 루트 Job
runBlokcing 함수를 호출해 코루틴이 생성될 경우 부모 Job이 없는 Job 객체를 생성한다.
이러한 Job(부모 Job이 없는 경우) 루트 Job이라고 하며, 구조화 시작점의 역할을 한다.
fun main() = runBlocking<Unit> { // 루트 Job 생성
println("[${Thread.currentThread().name}] 코루틴 실행")
}
위 코드의 구조는 다음과 같다.

그렇다면 자식 코루틴이 있는 경우의 구조를 살펴보자.
fun main() = runBlocking<Unit> {
launch(CoroutineName("Coroutine1")) {
launch(CoroutineName("Coroutine3")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
launch(CoroutineName("Coroutine4")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
launch(CoroutineName("Coroutine2")) {
launch(CoroutineName("Coroutine5")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
delay(1000L)
}
runBlocking 루트 코루틴 아래에 , 내부 launch 함수를 통해 #1, #2가 실행되고, #1 내부에서 #3, #4 , #2 내부에서는 #5가 실행된다.
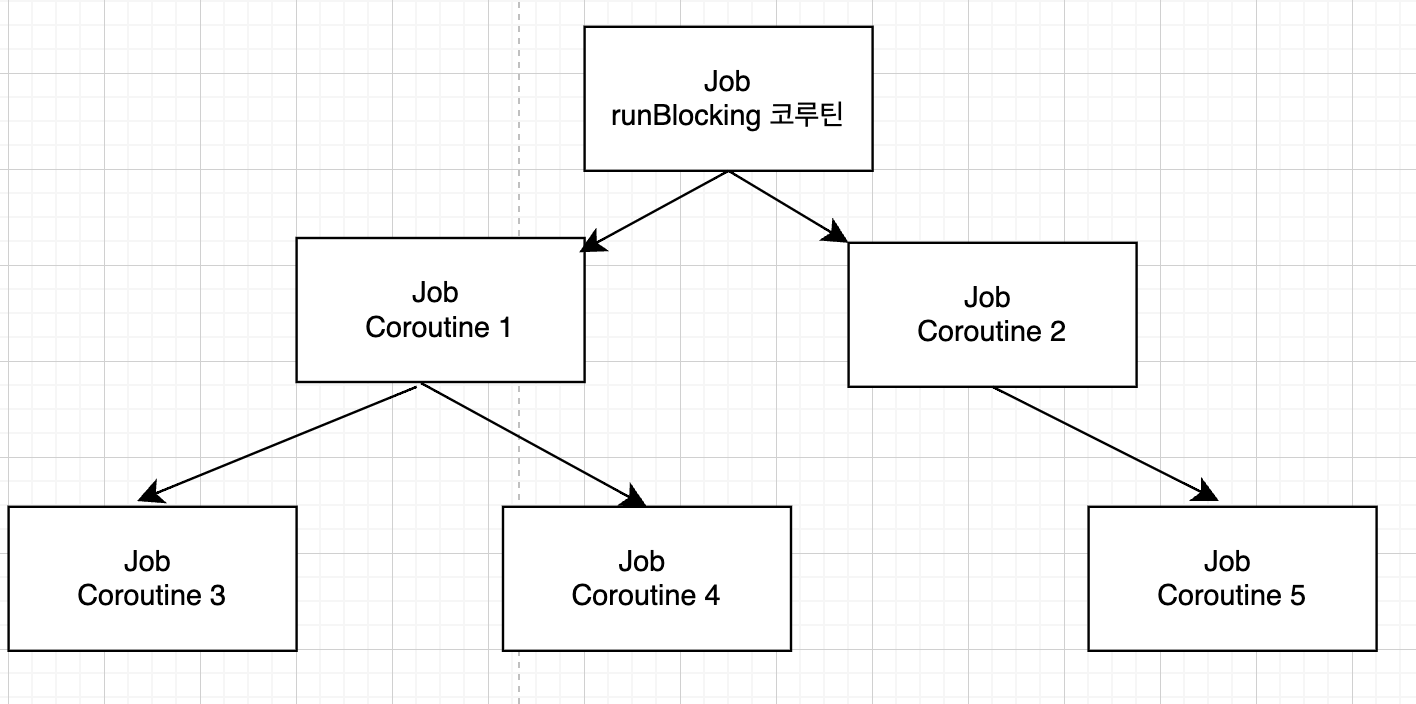
Job 구조화 깨기
CoroutineScope 사용해 구조화 깨기
CoroutineScope 객체는 Job 객체를 가질 수 있다.
Coroutine 객체가 생성되면 새로운 루트 Job이 생성되며, 이를 사용해 코루틴의 구조화를 깰 수 있다.
fun main() = runBlocking<Unit> {
val newScope = CoroutineScope(Dispatchers.IO)
newScope.launch(CoroutineName("Coroutine1")) {
launch(CoroutineName("Coroutine3")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
launch(CoroutineName("Coroutine4")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
newScope.launch(CoroutineName("Coroutine2")) {
launch(CoroutineName("Coroutine5")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
}위 코드에서는 runBlocking 함수를 통해 루트 Job이 생성되지만, 새로운 루트 Job을 가진 newScope가 생성된다.
이후 newScope의 launch 함수를 통해 자식 코루틴을 실행하게 된다.
해당 코드를 구조화하면 다음과 같다.
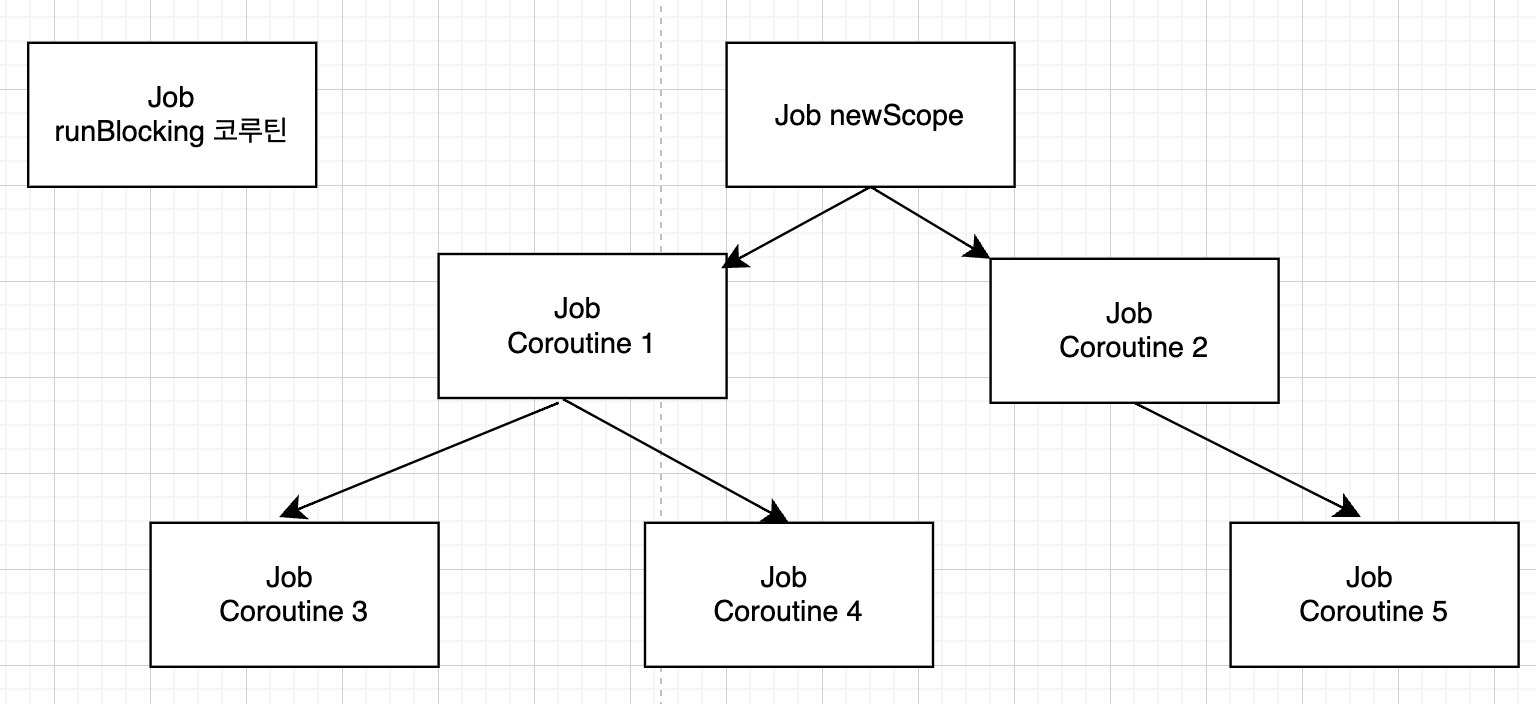
모든 자식 코루틴들이 newScope 하위에서 실행되기 때문에 runBlocking 코루틴은 자식 코루틴이 없고, 코드 실행 결과 아무런 결과 없이 프로세스가 종료되는 것을 확인할 수 있다.

이유는 newScope로 인해 구조화가 깨졌기 때문이다.
runBlocking 코루틴은 자식 코루틴들의 완료를 기다리는 상황이지만, newScope는 runBlocking 코루틴의 자식 코루틴이 아니기 때문에 다른 코루틴의 완료를 기다리지 않고 메인 스레드 사용을 종료해 프로세스가 종료되는 것이다.
이를 방지하기 위해 다른 코루틴이 실행 완료될 때까지 기다리는 임시 코드 delay를 추가하면 결과가 정상적으로 출력되는 것을 확인할 수 있다.

하지만 구조화가 깨진 코루틴이 실행 완료되는 것은 프로그래밍적으로 코드가 불안정해지기 때문에 지양해야 한다.
Job 사용해 구조화 깨기
코루틴의 구조화를 깨기 위한 또 다른 방법은 Job을 생산하는 것이다.
CoroutineScope를 생성하면 Job이 자동적으로 생성되고, 이를 이용해 코루틴의 구조화를 깨는 것이다.
그렇다면 Job 생산만으로도 가능하다는 얘기이다.
fun main() = runBlocking<Unit> {
val newRootJob = Job()
launch(CoroutineName("Coroutine1")+newRootJob) {
launch(CoroutineName("Coroutine3")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
launch(CoroutineName("Coroutine4")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
launch(CoroutineName("Coroutine2")+newRootJob) {
launch(CoroutineName("Coroutine5")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
delay(1000L)
}
Job()을 통해 새로운 루트 Job을 생성하고, 이를 CoroutineContext 인자로 넘기면 #1, #2의 공통 부모 Job이 된다.
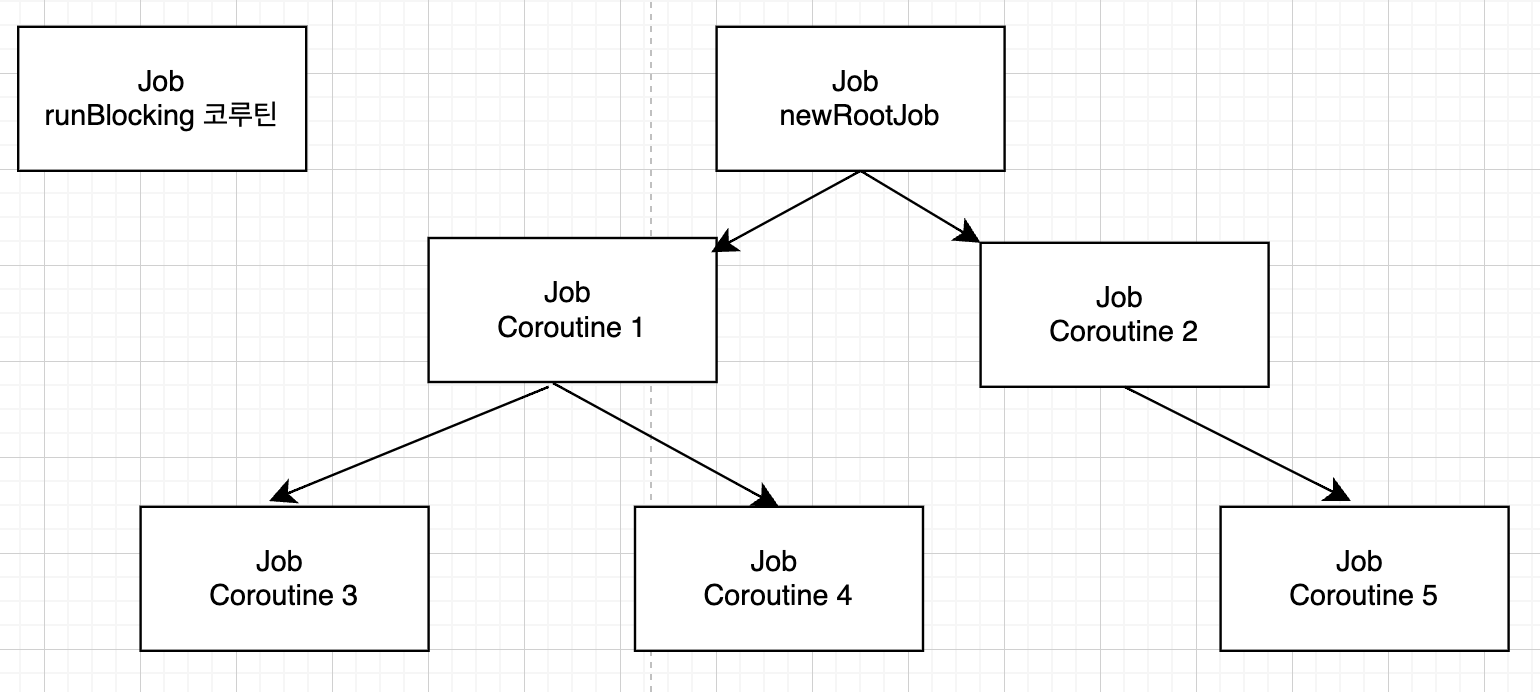
당연하게도, newRootJob을 취소 요청하면, 자식 Job 전체에게 취소가 전파된다.
만약 특정 Job이 취소되기를 원치 않는다면 newRootJob을 넘기는 것처럼 새로운 Job 객체를 인자로 넘겨주면 된다.
fun main() = runBlocking<Unit> {
val newRootJob = Job()
launch(CoroutineName("Coroutine1")+newRootJob) {
launch(CoroutineName("Coroutine3")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
launch(CoroutineName("Coroutine4")) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
launch(CoroutineName("Coroutine2")+newRootJob) {
launch(CoroutineName("Coroutine5")+Job()) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
delay(50L)
newRootJob.cancel()
delay(1000L)
}이 경우 Coroutine5는 newRootJob과 계층 구조가 끊어지기 때문에 정상적으로 실행되는 것을 확인할 수 있다.
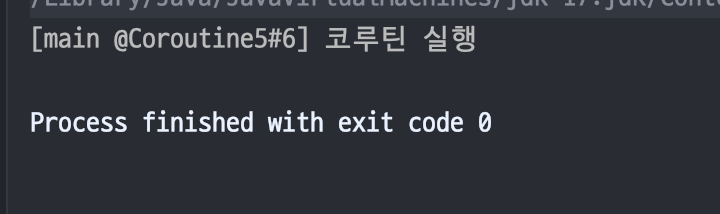
하지만 만약 Coroutine5가 생성되기 전, 부모 코루틴인 Coroutine2가 취소된다면 Coroutine5는 당연히 실행될 수 없다.
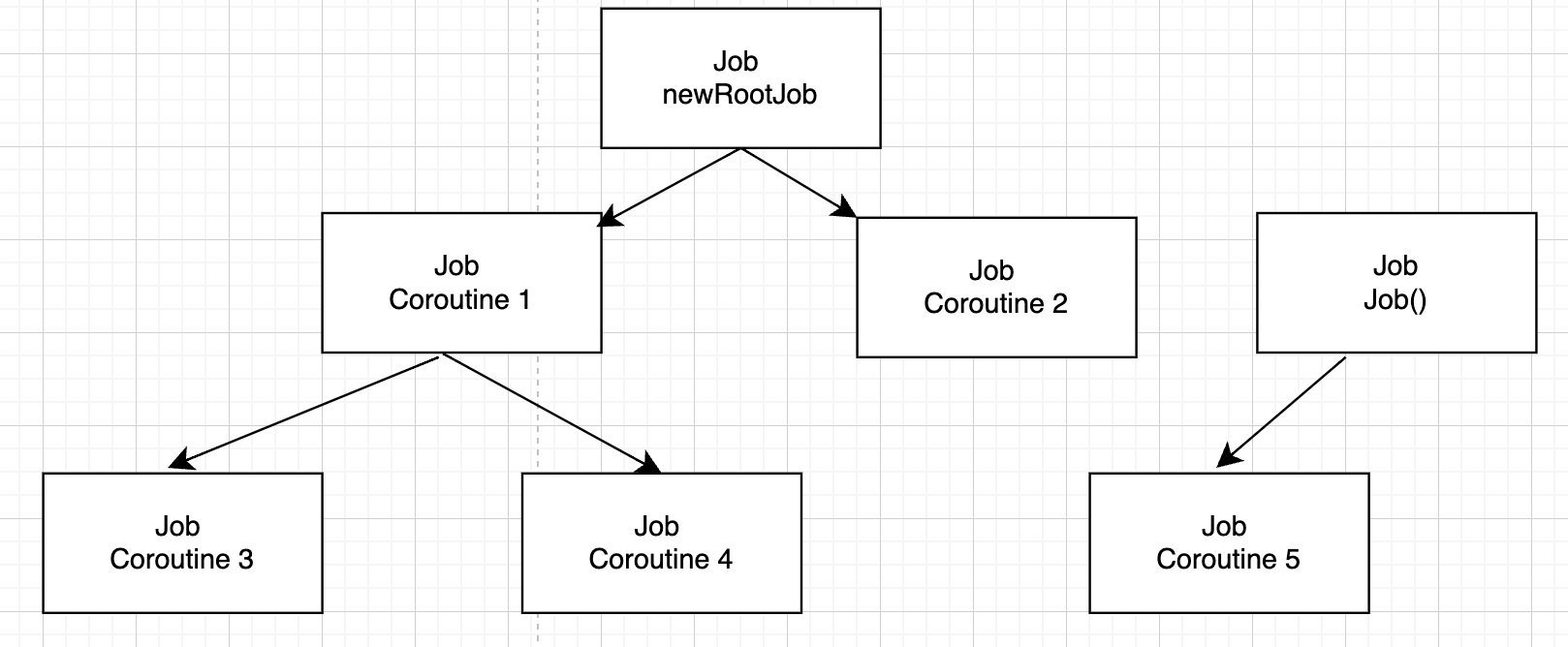
생성된 Job은 자동으로 실행 완료되지 않는다.
launch 함수를 통해 생성된 Job 객체는 모든 자식 코루틴들이 실행 완료되면 자동으로 실행 완료된다.
하지만 Job 생성 함수(Job())를 통해 생성된 Job 객체는 자식 코루틴들이 모두 실행 완료되더라도 자동으로 실행 완료 되지 않는다.
그렇기에 명시적으로 완료 함수인 complete 호출이 필요하다.
fun main() = runBlocking<Unit> {
launch(CoroutineName("Coroutine1")) {
val coroutine1Job = coroutineContext[Job]
val newJob = Job(parent = coroutine1Job)
launch(CoroutineName("Coroutine2")+newJob) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
}
}위 코드는 구조화가 깨지지 않은 코루틴 구조를 형성한다.
하지만 해당 코드는 종료되지 않는 오류 코드이다.
즉 코루틴의 실행 완료가 처리되지 않고 있는데, 이는 Job을 통해 생성된 newJob이 자동으로 실행 완료 처리되지 않기 때문이다.
코루틴의 특징 상 자식 코루틴들이 모두 완료되지 않으면 부모 코루틴도 실행 완료될 수 없기 때문에 무작정 대기하게 된다.
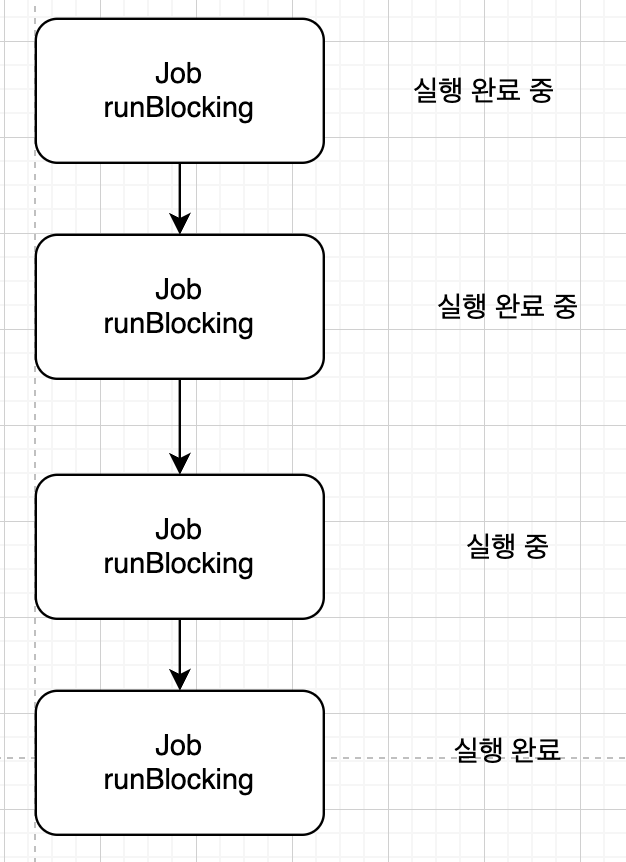
이 문제를 해결하기 위해선 complete 호출을 통해 명시적으로 Job의 상태를 실행 완료로 만들어야 한다.
fun main() = runBlocking<Unit> {
launch(CoroutineName("Coroutine1")) {
val coroutine1Job = coroutineContext[Job]
val newJob = Job(parent = coroutine1Job)
launch(CoroutineName("Coroutine2")+newJob) {
delay(100L)
println("[${Thread.currentThread().name}] 코루틴 실행")
}
newJob.complete()
}
}complete 함수를 통해 newJob은 실행 완료 중 상태로 바뀌며 자식 코루틴 실행이 완료되면 자동으로 실행 완료 중 상태로 바뀌어 부모 코루틴인 Coroutine1과 runBlocking 코루틴 모두 실행 완료 상태로 변하고 프로세스가 정상적으로 종료된다.
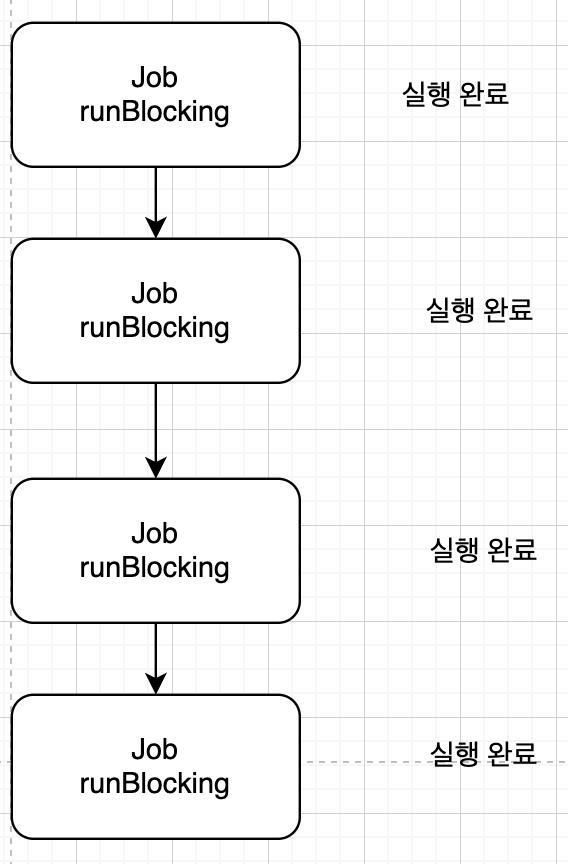
요약
- 구조화된 동시성의 원칙이란 비동기 작업을 구조화함으로써 비동기 프로그래밍을 보다 안정적이고 예측할 수 있게 만드는 원칙이다.
- 코루틴은 구조화된 동시성의 원칙을 통해 코루틴을 부모-자식 관계로 구조화해 비동기 프로그래밍의 안정성을 부여한다.
- 부모 코루틴은 자식 코루틴에게 실행 환경을 상속한다.
- 코루틴 빌더 함수에 전달된 CoroutineContext 객체를 통해 실행 환경을 변경할 수 있다.
- 코루틴 빌더가 호출될 때마다 새로운 Job 객체가 생성된다.
- Job 객체는 부모 코루틴의 Job 객체를 참조하며, 부모가 있을 수도, 없을 수도 있기 때문에 해당 타입은 nullable이다.
- Job 객체는 자식 Job 객체들을 참조할 수 있는 children 프로퍼티가 있다.
- 부모 코루틴은 자식 코루틴이 완료될 때까지 완료되지 않는다. 자식 코루틴이 실행 중이라면 부모 코루틴은 실행 완료 중 상태를 가진다.
- 부모 코루틴의 취소는 자식에게 전파되지만, 자식 코루틴의 취소는 부모 코루틴으로 전파되지 않는다.
- 코루틴의 구조화를 깨기 위해선 CoroutineScope 객체를 생성하거나 Job 생성 함수를 호출하는 방법이 있다.
참고
https://product.kyobobook.co.kr/detail/S000212376884
코틀린 코루틴의 정석 | 조세영 - 교보문고
코틀린 코루틴의 정석 | 많은 개발자들이 어렵게 느끼는 비동기 프로그래밍을 다양한 시각적 자료와 이해하기 쉬운 설명을 통해 누구나 쉽게 이해할 수 있도록 설명한다. 안드로이드, 스프링 등
product.kyobobook.co.kr
'Skils > Kotlin' 카테고리의 다른 글
| [코루틴의 정석] - CoroutineExceptionHandler(Chapter8-2) (0) | 2025.01.16 |
|---|---|
| [코루틴의 정석] - 예외 전파 제한(Chapter 8-1) (0) | 2025.01.14 |
| [코루틴의 정석] async와 Deferred(Chapter5) (0) | 2024.11.24 |
| [코루틴의 정석] 코루틴 빌더와 Job(Chapter4-2) (0) | 2024.11.23 |
| [코루틴의 정석] 코루틴 빌더와 Job(Chapter4-1) (0) | 2024.11.21 |