
●허프만 코드란?
- 데이터를 효율적으로 압축하기 위해서 만들어진 알고리즘.
- 탐욕법을 사용함.
데이터 파일은 통상적으로 이진 코드(binary code)로 표현한다.
각 문자는 코드 워드(code word)라고 하는 유일한 이진 문자열로 표현한다.
●fixed length binary code
- 각 문자를 표현하는 bit의 개수가 일정하다.
- 예를 들어 문자의 집합이 {a,b,c}라면 bit 2개만으로 문자를 코드화 할 수 있다.
- bit 2개로는 4개의 문자를 bit 3개로는 8개의 문자를 표현할 수 있다.
a : 00 b:01 c:11
이라고 가정하자.
만약 File이 ababcbbbc라면

결과 코드는 000100011001010110일것이다.
->18비트를 사용한다.
●variable-length binary code
- 각 문자를 표현하는 비트의 수가 다르다.
- 따라서 공간을 효울적으로 사용하는 코드 화방식을 만들 수 있다.
공간을 효율적으로 사용할려면 가장 많이 나오는 문자의 비트수를 적은 비트수로 할당해주면 된다.
위의 File에서 가장 빈번하게 나오는 문자는 'b'이다.
a: 10 b: 0 c: 11
여기서 왜 a가 00이 되지 못한다. 왜냐하면 a, b 두 개를 구별할 수 없기 때문이다.
a는 01도 되지 못한다. 왜냐하면 앞에 0이 나오는 경우에 a인지 b인지 뒤 숫자를 보지 않고는 구별할 수 없기 때문이다.
따라서 a를 10으로 코드화 해주는 것이다.

결과 코드는 1001001100011이다.
->13비트를 사용한다.
결과적으로는 variable-length binary code가 fixed-length binary code보다 비트를 적게 사용한다!!
●prefix code(전치 코드)
- 길이가 변하는 이진 코드의 특수 형태이다.
- 전치 코드에서는 한 문자의 코드 워드가 다른 문자의 코드 워드의 앞부분이 될 수없다.
- 예를 들어 'a'의 코드 워크가 01이라면 011은 'b'의 코드워크가 될 수 없다.
- 장점은 파일을 파스(parse)할 때 현재 파스 하고 있는 지점의 앞부분을 미리 볼 필요가 없다.
- 이진트리로 표현이 가능하다.
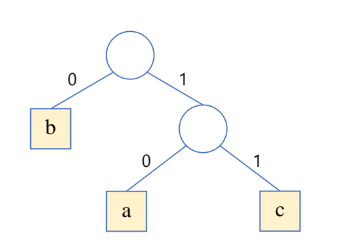
b : 0 a : 10 c : 11
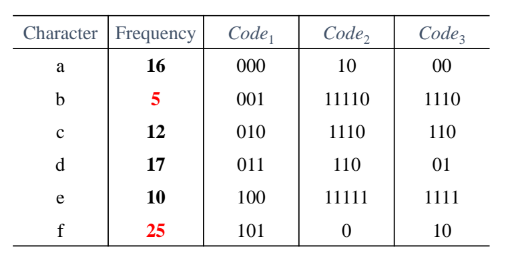
S={a, b, c, d, e, f} 일 때
- Fixed-length
사용된 비트 수는 (16+5+12+17+10+25) *3 = 255bit
- variable-length
사용된 비트의 수는 16*2+5*5+12*4+17*3+10*5+25*1=231bit
- Huffman code
사용된 비트의 수는 16*2 + 5*4+ 12*3 + 17*2 +10*4 +25*2 = 212bit
이진트리에서 차지하는 비트의 수 계산은

여기서 frequency는 나타나는 횟수고 depth는 트리에서의 깊이이다.
허프만 알고리즘
☆설계
- 우선순위 대기열(priority queue)을 사용한다.
- 우선순위가 가장 높은 원소는 빈도수가 가장 낮은 문자이다.
struct compare
{
bool operator()(node_ptr p, node_ptr q)
{
return p->freq > q->freq;
}
};
typedef priority_queue<node_ptr,vector<node_ptr>, compare> PQ;->빈도수가 낮은 순서대로 넣어서 pq에 정렬함.
- 빈도수가 가장 낮은 두 개를 뽑아 트리를 구축함.
- 그다음으로 낮은 원소를 뽑아 트리와 이어 붙임.(pq의 size가 1이 되면 종료함)
- pq의 size가 1이라는것은 모든 노드를 붙였다는 뜻임.
- 두 개를 뽑아 붙이는데 빈도수가 작은것이 왼쪽, 큰 것이 오른쪽에 붙음.
void huffman(int n, PQ &pq)
{
while (pq.size() != 1)
{
node_ptr p = pq.top();
pq.pop();
node_ptr q = pq.top();
pq.pop();
node_ptr r = create_node('+', p->freq + q->freq);
r->left = p;
r->right = q;
pq.push(r);
}
}- 문자열을 입력받고 숫자로 변환(encoding)
- 내가 방문한 노드의 symbol이 +가 아니라면, 즉 알파벳이라면 그때의 경로인 code값과 symbol을 map에다 넣어줌.
- 그러면 map의 key는 알파벳이고, value는 경로일것이다.
- 내가 방문한 노드의 symbol이 +일때
- 경로에다가 0을 넣고 왼쪽으로 이동-> 재귀호출이 끝난다면 경로를 초기화 해줌.
- 경로에다가 1을 넣고 오른쪽으로 이동->재귀호출이 끝나면 경로를 초기화 해줌.
- 내가 방문한 노드의 symbol이 +가 아니라면, 즉 알파벳이라면 그때의 경로인 code값과 symbol을 map에다 넣어줌.
void encode(node_ptr root, vector<int> &code, map<char, vector<int>> &decoder)
{
if (root->symbol != '+')
{
vector<int> ret;
ret.resize(code.size());
copy(code.begin(), code.end(), ret.begin());
decoder.insert(make_pair(root->symbol, ret));
}
else if (root != NULL)
{
code.push_back(0);
encode(root->left, code, decoder);
code.pop_back();
code.push_back(1);
encode(root->right, code, decoder);
code.pop_back();
}
}- 숫자를 입력받고 문자열로 변환(decoding)
- root는 루트노드, cnode는 현재 node, S는 입력받은 숫자, i는 현재 나의 진행상황(배열을 탐색해야할 i), ary는 문자열을 넣어줄 vector
- 첫번째로 현재 노드가 널인지 검사하고, i가 배열의 사이즈를 넘는지 검사함.
- 만약 현재 노드의 symbol이 알파벳이라면 그때의 알파벳을 넣고, 다시 root node로 되돌아감.
- 만약 현재 노드의 symbol이 +라면 나의 진행상황에 따라 방향이 달라짐.
- 만약 s[i]가 0이라면 왼쪽으로 이동
- 만약 s[i]가 1이라면 오른쪽으로 이동
void decode(node_ptr root, node_ptr cnode, vector<int> &S, int i, vector<char> &ary) //숫자를 문자
{
if (cnode != NULL && i <= S.size())
{
if (cnode->symbol != '+')
{
ary.push_back(cnode->symbol);
decode(root, root, S, i, ary);
}
else if (cnode->symbol == '+' && i <= S.size())
{
if (S[i] == 0)
{
decode(root, cnode->left, S, i + 1, ary);
}
else if (S[i] == 1)
{
decode(root, cnode->right, S, i + 1, ary);
}
}
}
}
코드 (주석추가 + 코드 수정+)
/*
우선순위 큐에 빈도수가 낮은것들로 넣어줌.
빈도수가 낮은거 2개를 선정해서 트리를 이어붙임.만약 다 붙엿다면 종료함.
작은것이 왼쪽 큰것이 오른쪽에 들어감.
*/
#include <iostream>
#include <vector>
#include <queue>
#include <map>
#include <string>
using namespace std;
typedef struct node *node_ptr;
typedef struct node
{
char symbol;
int freq;
node_ptr left;
node_ptr right;
} node;
struct compare
{
bool operator()(node_ptr p, node_ptr q)
{
return p->freq > q->freq;
}
};
typedef priority_queue<node_ptr, vector<node_ptr>, compare> PQ;
node_ptr create_node(char Symbol, int freq);
void huffman(int n, PQ &pq);
void encode(node_ptr root, vector<int> &code, map<char, vector<int>> &decoder);
void decode(node_ptr root, node_ptr cnode, string S, int i, vector<char> &ary);
node_ptr inorder(node_ptr root);
node_ptr preorder(node_ptr root);
int n, snum, cnum;
int main()
{
PQ pq; //우선순위큐설정
string Ary;
cin >> n; //문자의 개수 n
vector<char> x;
vector<int> y;
vector<char> cc;
node_ptr Node = (node_ptr)malloc(sizeof(node)); //동적할당
for (int i = 0; i < n; i++)
{
char b;
cin >> b;
x.push_back(b); //문자열 x에다가 문자를 넣어줌.
}
for (int i = 0; i < n; i++)
{
int c;
cin >> c;
y.push_back(c); //빈도값을 y에 넣어줌.
}
for (int i = 0; i < n; i++)
{
pq.push(create_node(x[i], y[i]));
// pq.push(Node);
}
huffman(n, pq);
preorder(pq.top());
cout << endl;
inorder(pq.top());
cout << endl;
cin >> snum;
vector<int> code;
map<char, vector<int>> m;
vector<int> ary;
for (int i = 0; i < snum; i++)
{
cin >> Ary;
encode(pq.top(), code, m); //문자열을 숫자로 바꿔주는 함수.
// m에는 해당 알파벳과 그의 따른 경로가 있음. //Ary는 내가 입력한 문자열임.
for (int j = 0; j < Ary.length(); j++)
{
if (m.find(Ary[j]) != m.end()) // map에 ary가 있으면 for문이 돌아가고 아니면 continue임.
{
for (int k = 0; k < m.find(Ary[j])->second.size(); k++) //내가 찾은 key의 경로를 출력해줌. 경로는 배열이니까 size만큼 해주면 됨.
{
cout << m.find(Ary[j])->second[k];
}
}
}
cout << "\n";
}
cin >> cnum;
vector<int> num;
for (int i = 0; i < cnum; i++)
{
string Num;
cin >> Num;
/*
for (int i = 0; i < Num.length(); i++)
{
num.push_back(Num[i] - 48); //입력받은 문자를 숫자로 바꾸고 인트배열에 넣어줌.
}
*/
decode(pq.top(), pq.top(), Num, 0, cc); //입력받은 숫자를 문자열로 교환해야함.
for (int i = 0; i < cc.size(); i++)
{
cout << cc[i];
}
if (i < cnum - 1)
cout << endl;
num.resize(0);
cc.resize(0);
}
}
node_ptr create_node(char Symbol, int freq)
{
node_ptr Node = new node;
Node->symbol = Symbol;
Node->freq = freq;
Node->left = NULL;
Node->right = NULL;
return Node;
}
void huffman(int n, PQ &pq)
{
while (pq.size() != 1) // pq가 1이 될때까지 이어붙임.
{
node_ptr p = pq.top(); //해당 큐에서 가장 작은 빈도수를 p
pq.pop();
node_ptr q = pq.top(); //해당 큐에서 두번쨰로 작은 빈도수를 q
pq.pop();
node_ptr r = create_node('+', p->freq + q->freq); // p와 q의 빈도수를 더해준 새로운 노드를 만듬.
r->left = p; //그 노드에서 작은것이 왼쪽 큰것이 오른쪽을 넣어주고
r->right = q;
pq.push(r); //큐에 넣어줌.
}
}
// huffman이 끝나면 트리가 완성됨.
void encode(node_ptr root, vector<int> &code, map<char, vector<int>> &decoder) //문자열을 숫자로 바꿔주는 함수
{
if (root->symbol != '+') //+가 아니라면 ret에 해당 알파벳을 넣어줌.
{
vector<int> ret;
ret.resize(code.size());
copy(code.begin(), code.end(), ret.begin());
decoder.insert(make_pair(root->symbol, ret)); // map에다가 간 경로와 그때의 알파벳을 넣어줌.
}
else if (root != NULL) //루트가 널이 아니라면 == +라면?
{
code.push_back(0); //왼쪽으로 이동하기 전에 경로 0찍음.
encode(root->left, code, decoder); //왼쪽으로 이동후
code.pop_back(); //왼쪽 탈출하면 오른쪽으로 이동할 예정이니 1을 찍고 오른쪽으로 이동함.
code.push_back(1);
encode(root->right, code, decoder);
code.pop_back(); //만약 탈출하면 경로 초기화
}
}
void decode(node_ptr root, node_ptr cnode, string S, int i, vector<char> &ary) //숫자를 문자
{
if (cnode != NULL && i <= S.size()) //노드포인터가 널을 가리키면 안되고 i는 입력받은 숫자열 사이즈까지만 반복함
{
if (cnode->symbol != '+') //문자를 만난다면 문자를 배열에 넣어주고 루트로 다시 되돌아가야함.
{
ary.push_back(cnode->symbol);
decode(root, root, S, i, ary);
}
else if (cnode->symbol == '+' && i <= S.size()) //알파벳이 아니라면
{
if (S[i] == '0') //경로가 0일때는 왼쪽으로 옮겨줌.
{
decode(root, cnode->left, S, i + 1, ary);
}
else if (S[i] == '1') //경로가 1일때는 오른쪽으로 옮겨줌.
{
decode(root, cnode->right, S, i + 1, ary);
}
}
}
}
node_ptr preorder(node_ptr root) // root출력 왼쪽 반복 막히면 다시 오른쪽
{
if (root != NULL)
{
cout << root->symbol << ":" << root->freq << " ";
preorder(root->left);
preorder(root->right);
}
return root;
}
node_ptr inorder(node_ptr root) //왼쪽왼쪽왼쪽왼쪽막히면 출력 오른쪽 오른쪽 마히면 위로올라감.
{
if (root != NULL)
{
inorder(root->left);
cout << root->symbol << ":" << root->freq << " ";
inorder(root->right);
}
return root;
}이 문제를 풀면서 map, 우선순위 큐, 구조체 포인터에 개념이 부족하다는 것을 깨달았다.
'Skils > Algorithm' 카테고리의 다른 글
| 알고리즘[C++]- Backtracking을 이용한 부분집합의 합(subset_sum)순서쌍 구하기. (0) | 2022.05.15 |
|---|---|
| [C++]-백트래킹(Backtracking)이란? + n-Queens문제 (0) | 2022.05.06 |
| 분할가능 배낭 문제(Fractional Knapsack Problem)-C++ (0) | 2022.04.30 |
| 알고리즘 - Greedy (dead-line Scheduling Problem) (0) | 2022.04.29 |
| 알고리즘- 시간복잡도 분석(Time complexity Analysis) (0) | 2022.04.19 |