
DBMS는 정보를 disk에 저장한다.
Read : main memory(RAM)으로부터 디스크로 데이터를 전송한다.
Write : Ram에 있는 data를 disk로 전송한다.
위와 같은 오퍼레이션(Read & Write)은 비용이 비싸기에, 주의해야 한다.
Database는 magnetic disk에 데이터를 저장한다.
📕저장공간의 3개의 개층
- Primary Storage(주 기억장치)
- 현재 사용하고 있는 data
- CPU main mermoy , cache memory
- Secondary Storage(보조 기억장치)
- main database의 disk로 사용
- Magnetic disk, flash memory , solid-state drives. ex) HD
- Tertiary Storage
- backup 용도
- 저장공간이 크고, 싸고, 오래보관, 하지만 읽어올 때 오래 걸림? -> 처음부터 읽어야 하기에
- Removable media
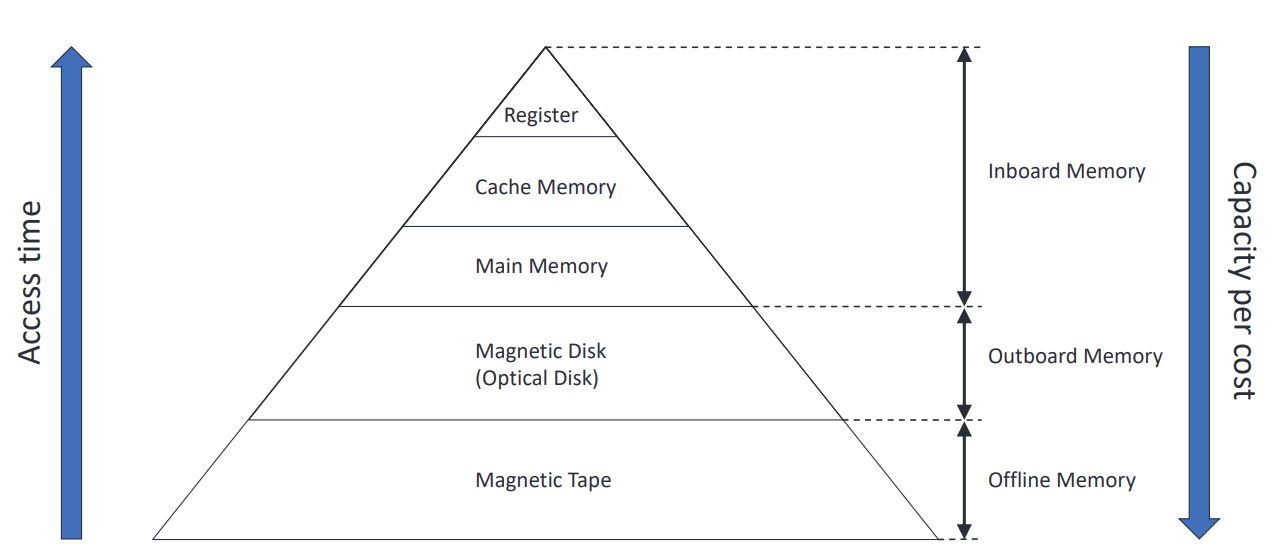
- 상위 계층으로 갈 수록 Access time이 줄어들며, 비용이 비싸진다.
📕더 세부적인 계층도

- CPU와 Cache는 휘발성, Physical memory는 비휘발성
📕Persistent data -보존되어야 하는 정보(Nonvolatile)
데이터베이스는 대부분 많은 양의 데이터를 오랜 기간 동안 저장한다.
그러한 데이터 저장은 보조기억장치(secondary storage , ex) magnetic, SSD disks)에 한다.
왜냐하면
- main memory에 저장하기에는 main memory가 너무 작다.
- 그리고 전원이 꺼진 후에 사라지면 안된다. (main memory는 휘발성이기에 전원이 꺼지면 사라짐)
- 주 기억장치보다 가격이 훨 씬 저렴하기 때문.
📕Transient data(volatile)
- persistent data와 반대
- 프로그램이 실행되는 동안만 존재한다. e.g ) malloc()
📕Organizing storage
- Primary file organizations는 결정한다.
- file records를 물리적으로 disk에 배치할 방법
- recods가 접근할 방법
- Heap file(unordered file) : 순서 없이 제일 마지막에 있는 file 뒤에 저장
- Sorted file(sequential file) : sort key field를 이용하여 record를 정렬하여 저장(유지 보수 비용 발생)
- Hashed file : hash key field에 적용되는 hash function를 사용하여 disk에 저장할 위치 결정
(hash value에 따라 서로 다른 위치에 저장되어 같은 key값을 갖는 tuple 끼리끼리 묶여서 저장됨) - Tree - structured file(B-trees)
- Column-based file : column 단위로 record 저장 (row_id 정보도 같이 저장)

- Secondary organization ( or auxiliary access structure)
- Primary file organization에 추가적으로, file record에 효율적인 접근을 위해 alternate filed를 기반으로 사용
- indexes ( index file 접근 -> primary file 접근)
📕Disk
- random access addressable device
- Ram과 disk blocks의 unit으로 data를 주고 받는다.
- block(or sector) address는 다음과 같은 구성요소를 가진다.
- Cylinder number, track number, track에 있는 block number 또는 block에 있는 sector number
- Disk I/O controller는 block address를 제공한다.
- 대부분의 최신 disk drivers는 controller에 의해 LBA(logical Block Address)가
오른쪽 block에 자동으로 매핑된다.
- Disk read
- 처리할 disk block의 LBA를 disk drive buffer에 복사한다.
- disk drive buffer에 이미 있다면 복사 X
- Disk Write
- buffer의 contents가 LBA와 함께 disk block으로 복사됨.
📗Secondary storage device of choice
- Main advantages over tapes : random access vs sequential
- random access : 내가 찾고자 하는 data를 찾는 것, sequential : 차례대로 읽음
- Data is stored and retrieved in units called disk blocks or pages
Main memory(Volatile)와 cpu는 Transient Data를 주고받고,
Secondary storage(Non-Volatile)와 cpu는 Persistent Data를 주고받는다.
📕Disk Architecture

- Physical layout
- Disk는 magnetic platters의 stack
- 각 platters의 표면은 track으로 구성됨.
- tracks는 sector로 나눠진다.
- sector : storage의 기본 unit
- sector ID, data, Error-connection code, sync. fields, or gaps로 구성된다.
- block or page : sectors의 그룹(read/write의 unit), 전형적으로 4k bytes(=8 Sectors)
- disk head는 spindle이 원하는 sector를 찾기 위해 회전하는 동안 (동일한 cylinder) 내에서
원하는 트랙을 찾기 위해 움직인다.
- Accessing a Disk
- Seek time : 원하는 track을 찾기 위해 disk head를 움직이는데 드는 시간
- Rotational delay : 원하는 track에는 도달했고, 원하는 sector가 (read/write) head
아래에 위치할 때까지 회전하는 데 걸리는 시간- 최소 : 0 ~ 최대 : 한 바퀴 전체 -> 평균적으로 full rotation time의 절반
- Transfer time : bit의 disk block을 전송하기 위해 사용되는 시간
- I/O cost를 낮추는 요소
- reduce seel
- rotation delays를 낮춰야 함.
📕Data access time을 향상하기 위한 기술
- Buffering of data (in main memory)
- old data가 처리되는 동안 new data가 buffer에서 대기
- Proper organization of data on disk
- related data를 이웃한 block에 위치, data block를 헤드에 가깝게 위치시킨다.
-> inner track에 대해 disk arm이 안까지 들어가야 하는 성능의 저하를 방지
- related data를 이웃한 block에 위치, data block를 헤드에 가깝게 위치시킨다.
- Reading data ahead of request(prefetching)
- disk read에 대해 track의 남은 block 또한 같이 read 한다.
- Proper scheduling of I/O requests
- total access time을 최소화하는 것을 목표로 함.
- elevator algorithm : disk arms는 단방향으로 움직인다.
- writes를 임시적으로 보관하는 log disk의 사용
- 적혀야 하는 모든 블록은 seek time을 줄이기 위해 log disk로 이동
- SSDs의 사용
- 기계적인 지연은 없지만 비쌈.
📕Buffer Management

- data request에 응답. (e.g mysql query)
- 어떤 buffer를 사용할지, buffer에 어떤 페이지를 새로 할당할지를 결정
- 사용 가능한 main mermoy storage를 buffer pool로 탐색?
- 각 page에 대해 두 가지 타입의 정보를 저장한다.
- Pin count : 해당 페이지가 요청된 횟수
- Pinning : pin-count를 증가시킴
- pin-count가 0이라면 -> unpinned, 그렇지 않으면 page를 쫓아버릴 수 없다.
- high pin count를 가지는 page는 자주 사용한다는 의미이기에, buffer에 둔다.
- 만약 pin count가 0이라면 그 페이지는 교체될 후보다.
- Dirty bit
- 메모리 안에 있는 페이지가 바뀌었다는 것을 보여주는 표시
- 초기에는 0, program에 의해 해당 page가 update 되면 1로
- set to 1 : Disk 상의 page 정보와 main memory에 올라온 page 정보 간의 불일치가 발생.
불일치를 나타내기에 Disk에 update를 해줘야 한다는 것을 나타냄.
- Pin count : 해당 페이지가 요청된 횟수
📕page request
- Buffer manager는 요청된 page가 buffer pool에 있는 buffer에 이미 존재하는지 확인한다.
- page가 존재한다면, manager는 해당 page의 pin-count를 증가시키고(pinning)
해당 page의 내용을 copy 해서 전달 - 존재하지 않는다면 , manager는 아래의 행동을 수행한다.
- free page (or frame)을 선택
- 만약 free page가 없다면 하나의 페이지를 선택해야 한다.
- replacement policy를 사용하여 대체할 페이지를 선택한다.
- 만약 선택된 페이지의 dirty bit가 1이라면 업데이트를 해야 한다는 뜻이므로
manager는 해당 page를 disk에 wirte 하고, 비워준다. - 만약 선택된 페이지의 dirty bit가 0이라면 업데이트를 해줄 필요가 없으므로, disk에 write 할 필요 X
- 해당 페이지를 비워주고, dirty bit를 0으로 만든다.
- 요청된 block을 비워준 page로 read 한다.
- 해당 페이지의 pin-count를 증가시키고, 페이지의 address(frame id)를 요청자에게 전달해준다.
- page가 존재한다면, manager는 해당 page의 pin-count를 증가시키고(pinning)
📕Buffer Replacement Strategies
📗Least recently used (LRU) : 가장 오랫동안 사용되지 않은 page를 희생하는 전략
- 직관적이고 간단하며, 자주 사용하는 page를 반복적으로 접근하는 작업에 적합함.

이렇게 track에 머무른 time 별로 정렬된 page들 중에서 가장 오래된 page를 선정해서 새로 접근한 page와
교체해주는 방식이다. 가장 최근에 access 한 page가 왼쪽에 위치하고 오래된 page가 오른쪽에 위치한다.
그러면 가장 오른쪽에 있는 page가 이제 replace 될 후보 페이지다!
- 문제점
- 가격이 비싸다.
- 순차적 작업
📗Clock replacement Policy
- An approximation of LRU or round - robin variant of LRU
- frame 별로 referece bit를 저장함.
- 2번째 기회 bit라고 생각하면 편함.
- pin-count가 0이 돼도 한 번의 기회를 더 부여함.
- 만약 pincount 가 0이 되면 ref bit를 turn off으로 변경
- 즉 replace 될 page를 찾는데 pin-count가 0인데 ref bit가 turn on 상태라면 ref bit를 turn off
한번의 기회를 더 부여 - 만약 pin-count가 0이고, ref bit가 off 라면 그 페이지를 replacement 해준다.
📕Buffering for concurrency

- Interleaved concurrency의 경우, 각 task를 쪼개어 시간대 별로 수행
- Parallel execution의 경우 각 task를 동시에 수행
- Buffering은 processes가 병렬적으로 동시에 실행될 때 가장 유용하다.
📕Double buffering
- Disk를 read 하는데 2개의 buffer를 사용

- block transfer가 완료되면, CPU는 해당 block에 대한 처리를 시작할 수 있다.
- 동시에 disk I/O controller (processor)는 다음 block을 읽고, 다른 buffer에 전송할 수 있다.
- 따라서 여러 blocks에 대한 continuous read에 유용하다.
📕Placing File Records on Disk
📗disk에 records를 저장하는 3가지 옵션
- 만약 모든 어트리뷰트가 고정된 길이를 가진 경우, 각 records를 그대로 저장함.
- 프로그램은 각 attribute를 찾을 수 있는 위치를 알고 있음.

- fixed-length field와 variable-length field를 혼합한 경우 특수 문자를 사용하여 분리 표시

- 속성의 하위 집합만 저장되는 레코드의 경우 인덱스를 사용하여 저장되는 속성을 나타냅니다.

File records는 disk block에 할당된다.
- Block은 disk와 memory 사이의 data transfer의 기본 단위
- block의 크기가 record의 크기보다 크거나 같다면, 한 block의 여러 개의 record가 저장될 수 있다.
📕Spaaned records
- record는 single block보다 큰 경우, 해당 record를 분리하여 여러 block에 저장
- first block의 끝에 남은 record를 저장하고 있는 block에 대한 pointer를 저장.

📕Unspanned records
- record의 크기가 block 보다 작은 경우
- pointer를 사용하지 않아서 빠르지만, block의 공간이 낭비된다.

📕Block factor
- 한 block당 평균 record의 수(bfr) = B/R [ B= block size, R= record size]
- fixed-length records
- Unused space -> B-(bfr * R) bytes
- variable-length records
- 따라서, 스팬 조직을 사용하는 r 레코드에 필요한 블록의 수
- bfr은 r개의 records의 필요한 block의 수 계산하는 데 사용될 수도 있다.
- b=[r/bfr] blocks r: file의 record 수
- Quiz
- How many blocks do we need to store a file of 1,000 records?
- Number of records (R) : 1000
- Record size : 15 bytes
- Block size : 4 Kbytes
- what is bfr?
- bfr은 block당 평균 record의 수
- 그러면 어떻게 구해야 할까요-> 블록 크기를 레코드 크기로 나누면 되겠죠
- bfr = B/R = 40000/15 = 266.
- 즉 하나의 블락에 266개의 record가 들어간다.
- 그러면 1000개의 record를 저장하는데 필요한 블록 수는?
- b=[r/bfr] = [1000/266] = [3.759] -> 즉 4개의 블록이 필요하다.
- Unused space(사용되지 않는 공간) : B - (bfr * r ) bytes = 4000 - 266*15= 10 bytes
- How many blocks do we need to store a file of 1,000 records?
📕Allocating File Blocks on Disk
- Continous allocation : file blocks는 순차적으로 할당
- 읽는 속도가 빠르지만, 확장 문제 발생
- Linked allocation : 각 file block은 다음 file block을 가리키는 pointer를 포함
- 확장이 쉽지만, 읽는 속도가 느림.
- Clusters :Continuous와 Linked의 결합
- Indexed allocation : 하나 또는 이상의 index blocks이 실제 file blocks에 대한 pointers를 포함
- index file을 통해 flie block에 접근. (hash file이 예다)
📕Types of Databases File Organizations
- Files of unordered records
- Heap Files
- Files of ordered records
- Sorted Files
- Files of hashed records
- Hashed indexes
📕Heap Files (unordered records)
- 가장 간단하고 기본적인 organization 방식

- record insertion
- records는 삽입되는 순서대로 저장됨.
- 새로운 record는 file의 가장 끝에 저장.
- insertion에 대해서 매우 효율적이다.
- file의 마지막 disk block은 buffer로 복사
- 새로운 record 삽입
- 해당 block을 다시 disk에 write
- 마지막 file block의 주소는 file buffer에 남아있다.
- 작고 부피가 큰 data에 대해서는 적합하지만, 규모가 큰 데이터베이스에는 적합하지 않다.
- records는 삽입되는 순서대로 저장됨.
- record search
- binary search가 불가능하다.
- 따라서 record를 탐색하는 것은 비싸다. (linear search)를 하기에.
- 평균적으로는 b/2 횟수지만, 최악의 경우 모든 block을 탐색한다.
- record delete
- 과정
- 먼저 해당 block을 탐색
- block을 buffer로 복사
- buffer에서 record를 삭제
- block을 다시 disk에 write
- 공간적 낭비가 심하고, 주기적으로 재편성한다.
- 과정
- record sorting
- 파일의 정렬된 복사본을 생성한다.
- 하지만 크기가 큰 disk file에 대해서 비용이 비싸다.
📕Sorted(Sequential) Files
- 물리적으로 key field에 대해 정렬하여 file 저장 (key field = ordering field)
- 이점
- 필드 순서대로 읽기에 매우 효율적이다.
- 다음 record를 찾는데 disk address가 필요하지 않다.
- 정렬되어 있기에 다음 record는 같은 block 내에 존재하기 때문
- Search를 하는데 빠르다. (정렬되어있기에)
- binary search 가능
- O(log2(b))
- 단점
- records를 삽입하고, 삭제하는데 비용이 비싸다.
- 할떄마다 위치를 특정시켜줘야 하기에
- 정렬된 필드를 수정하면 위치가 변경될 수 있으며, 삭제 후 삽입이 필요합니다.
- records를 삽입하고, 삭제하는데 비용이 비싸다.
'Computer Science > DataBase' 카테고리의 다른 글
| [Database]- B-Tree , B+-Tree (0) | 2022.12.18 |
|---|---|
| [Database] - Indexing (0) | 2022.12.18 |
| [Database] - 정규화(Normalization) (0) | 2022.12.17 |
| [데이터베이스]- 수강신청을 위한 수강꾸러미 시스템 구현(1) (1) | 2022.12.03 |
| [Database] -advancedSql (2) | 2022.10.18 |